
From Hacker News to Reading List: Using LLMs to Extract Book Recommendations in Seconds
A practical example of how LLMs can help with mundane tasks

In my last post, I discussed LLM context windows, and some accompanying challenges. I recommend reading that post first, because in this post we’re diving right into a practical example. 🤿
premise
I stumbled upon a Hacker News post with a bunch of book recommendations. The impassioned comments motivated me to compile a list. However, once I saw the post was over 100 comments, I knew I had to automate it. A perfect excuse to burn some OpenAI credits!
Fun aside, I thought it’d be a great use-case for an LLM because the comments were highly irregular, so traditional approaches wouldn’t work well, or quickly enough. Formatting varied a lot, and not every comment was guaranteed to have a recommendation.
Here are some snippets of comments:
Deploy Empathy, Michele Hansen
This comment has a nicely formatted recommendation.
The Charisma Myth - to help w/ charm for sales
This is well formatted, but lacks the author.
Do you have an example nugget that stuck with you?
This comment doesn’t have a recommendation at all.
6. The Upstarts by Brad Stone
This comment is well formatted, but differently.
the code
The full source code for this script is available on GitHub.
My inital thought was to scrape the post using beautifulsoup, get the text contents of the page (sans HTML), and feed it into the GPT3.5 API with a cool prompt. This approach fails out of the gate because the page contains over 44,000 characters, which translates to about 11,000 tokens, vastly exceeding the LLM’s context window.
Intuitively, my next move was to compile the page as a list of comments rather than as a single string.

But now what? I didn’t want to send the comments one-by-one because that would take forever (minutes) and be token-inefficient ($), since prompts would be repeated with each request.
So batching requests was next, but this had to be done intelligently because the GPT3.5 API has a 4,096 token limit.
getting started
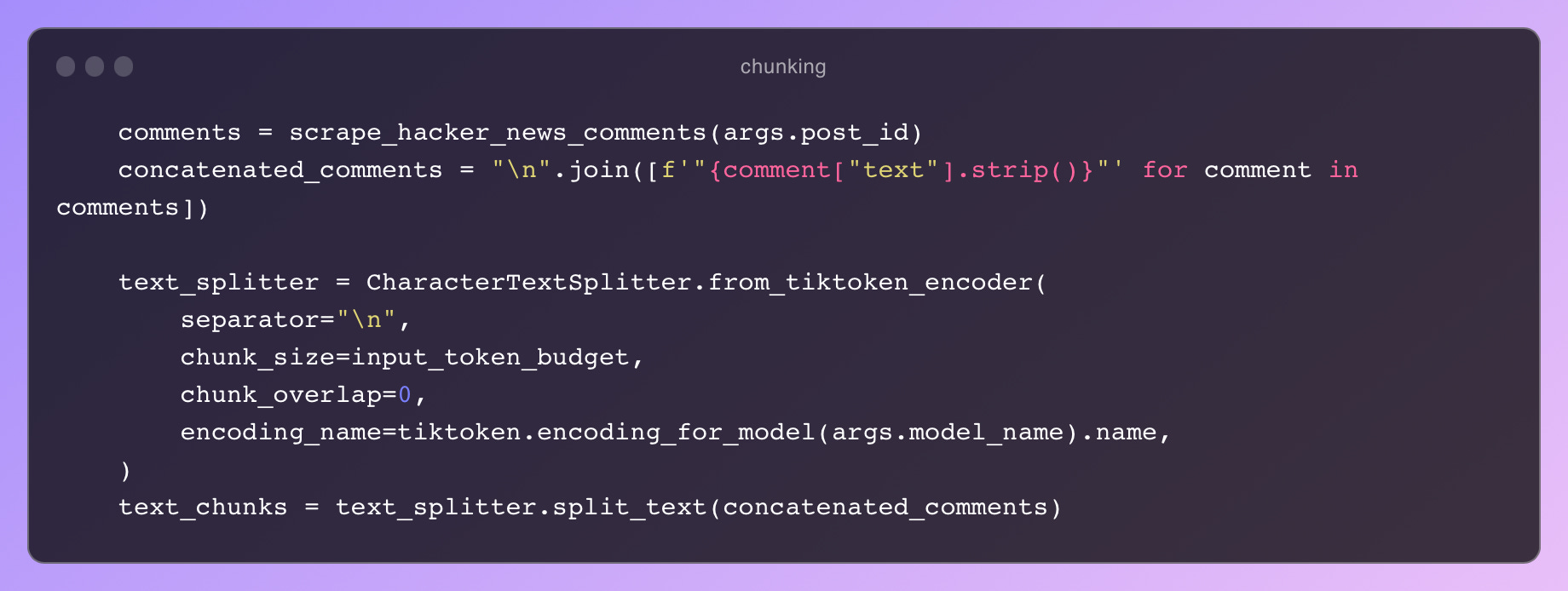
This is when I began using Langchain. Langchain has many abstractions, tools and integrations, but I started simply with a CharacterTextSplitter which batches text documents based on a certain token limit (edit: I later learned that I should be using TokenTextSplitter for this, since it’s token-aware, but CharacterTextSplitter worked well enough).
Put simply, imagine you have a book, and you’d like to break it down into pages because the context window can only support a couple of pages at a time; the various TextSplitters help with this. There are more sophisticated splitters like NLTKTextSplitter (a personal favorite) that draw boundaries more intelligently (sentences in the case of NLTK), but the simpler ones work well enough.
prompting
With the sketch of batching out of the way, two questions remained:
(1) how big should chunks/batches be? (the input token budget)
(2) how do we get the model to use the chunks with prompting?
I worked backwards by answering (2) since the prompt directly impacts the remaining tokens in the context window. After much iteration, I settled on the following:
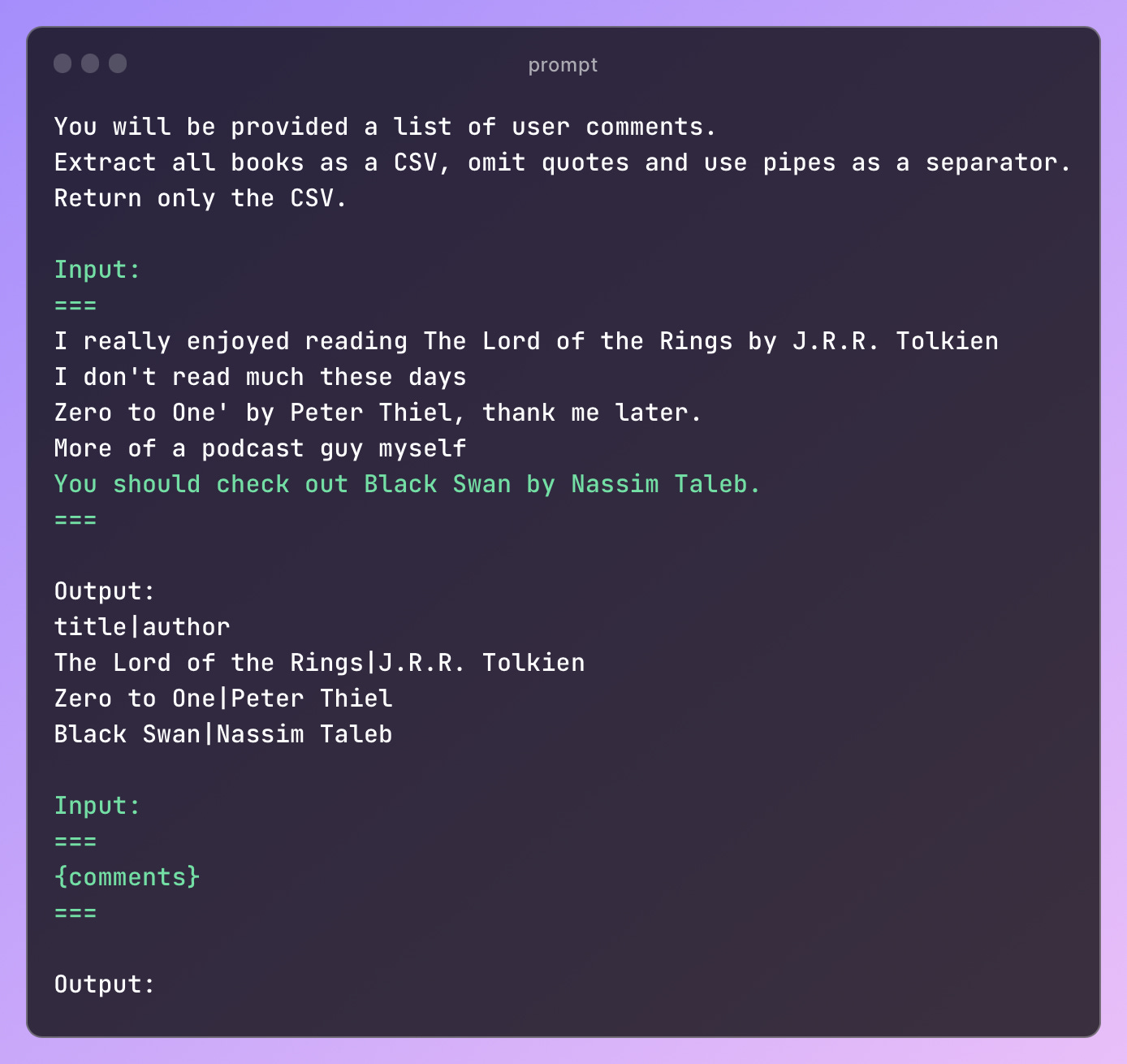
The notable parts of this prompt:
Natural language instructions for the task.
A desired output (CSV).
Examples for few-shot learning.
A placeholder for input (the {comments} part).
token budgeting
The prompt limits the remaining tokens in the context window (token budget below), which informs (1), the batch size.
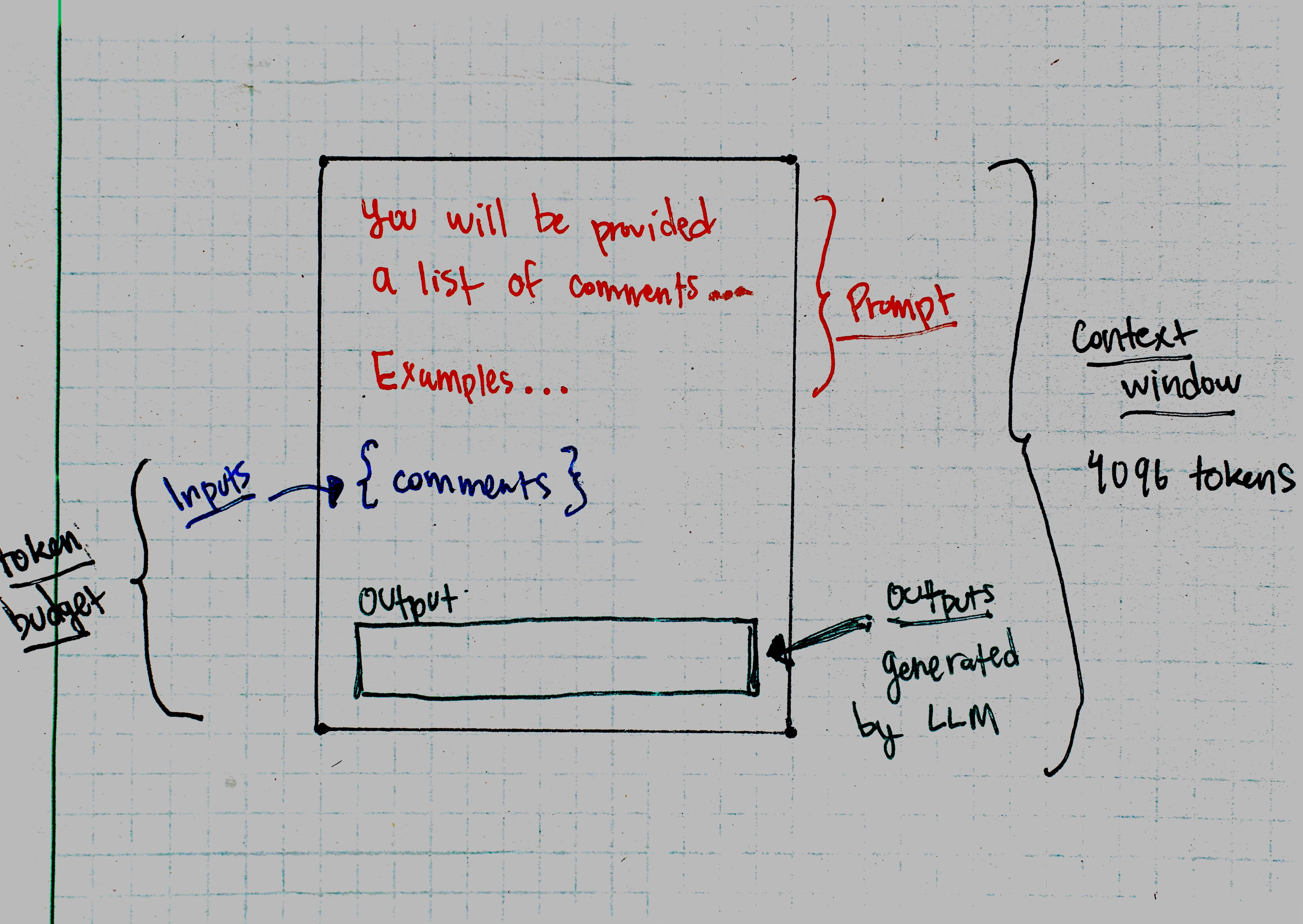
I played around with how to divide the token budget amongst the inputs and outputs. Eventually I decided on 50/50 to err on the safe side1, since there is a risk the outputs get cutoff if not enough tokens are allotted.
With the token budgeting complete, the rest of the code calls the OpenAI API using Langchain, and writes the output to a file:

Async code is not strictly necessary, but I was impatient and wanted the requests to complete as fast as possible.
pro-tips
Several small lessons helped make this script work dependably and affordably:
Prompt design matters for reliability. I explicitly asked the model to:
Output only my desired format.
I described the parameters of that output format (pipe delimited without quotes).
Pre-processing matters for efficient token usage and reliability. I stripped input data (the comments) of anything that wouldn’t be useful for the task, like HTML, whitespace, etc. This will vary by use-case.
Whitespace matters! Formatting like spaces and newlines count against the token budget, so it’s important to be judicious with their use2, especially for input data, where a lot of the budget is spent.
The choice of output format matters. Initially I used JSON but settled on CSV because it’s significantly more token-efficient. I saved 40% of token usage by switching to CSV.
Field names are not repeated.
Internal structure is minimal (eg delimiters). With JSON a bunch of tokens are used on commas, colons and curly braces.
CSVs are innately newline-delimited3, so a more advanced use-case could leverage this to stream records as they are returned by the API, as opposed to waiting for the entire response.
Mind the timeouts. I wasted a lot of calls because the default timeout of 60 seconds in Langchain. Depending on your use-case (ie how much data you put into the prompt), and the model you use, you may need to wait a while, so change things accordingly.
Since this was a text extraction task, I didn’t need a lot of “creativity” so set the temperature to 0. Temperature is a subject unto itself, but a rough mental model is that the lower it is, the more deterministic the output is.
tools
Prompts and token budgeting required some iteration. I found the following tools very helpful in refining this script:
OpenAI web tokenizer: this tool visualizes token usage for a piece of text. It’s essentially how the model “sees” and generates text.
tiktoken: This is a python package that tokenizes text. This is essentially the programmatic version of the web tokenizer. I use it for programmatic token budgeting, since it can operate on user-specified strings.
OpenAI Playground: this is a web console OpenAI provides to experiment with the API. I find it very useful for quickly prototyping a prompt, without needing to pipe everything together in code.
conclusion
I was impressed with the results. And though it was imperfect, it saved me a lot of time.

That said, for this personal use-case this approach may not be economically viable, since total API costs varied from a couple of cents to several cents per page.

I’ve thought of these potential improvements:
Using a simpler model or heuristic to classify whether a comment contains recommendations in the first place. This would could save some token usage in the more expensive model4.
Use a bin packing algorithm to better bucket inputs into requests. At this scale, I don’t think this is worthwhile, but I can imagine some requests didn’t fully utilize the entire context window.
This script can be generalized to extract other entities fairly easily. The entity type and the examples in the prompt would need to be changed, and these can be placeholders, just like the inputs.
If you’re curious about LLMs, I recommend finding a little problem you have and solving it with an LLM; they’re very approachable and fun to use.
I ran into issues where I didn't allocate enough tokens to the output (2/3 to 1/3 split), which meant certain items were just not picked up. It's wise to leave some wiggle room, especially when the results you expect are highly variable (eg one 100-token chunk may have 2 book recommendations with the user's opinion, whereas another may be a list with 10 recommedations).
This is why there’s strange formatting (it’s outdented) of the system prompt in the source. Long-term is pays to keep the prompts in a separate file or system, like a database.
I tried this approach briefly, but saw inconsistent performance. Certainly more prompt engineering would help here.